

By Inc42 Media
In this brilliant yet turbulent era of generative AI (GenAI), OpenAI’s ChatGPT is undoubtedly one of the best breakthroughs. Using natural language understanding and processing (NLU & NLP), the intelligent chatbot has been built on a series of foundational large language models, or LLMs, ‘deep-learning’ from human languages, behaviours and knowledge repositories and generating new content in multiple formats and multiple languages.
Whether it is a search generated on the World Wide Web, a complex piece of code writing, or the making of a creative wonder, ChatGPT can transform the output every time, demonstrating the true potential of the ongoing AI revolution. OpenAI further claims that its flagship GPT-4o (‘o’ stands for omni) is faster than the chatbot’s predecessors and will sound more conversational in responding to prompts.
Could this be a definitive step towards the concept of artificial general intelligence, a computing ecosystem on par with human intelligence, with the capability to self-learn? It is a matter of endless debate, with no concrete conclusion in sight. Meanwhile, the GenAI market across industries will likely witness a phenomenal surge from an estimated $67.2 Bn in 2024 to $967.6 Bn by 2032, growing at a CAGR of 39.6% during the forecast period.
McKinsey & Company further estimates that GenAI and other technologies can automate work activities that currently absorb 60-70% of employees’ time. Combining GenAI with different technologies will also add 0.5 to 3.4 percentage points annually to productivity growth. As this is bound to create a huge economic impact, Google, Meta, Amazon and their ilk have rushed to commercialise their AI projects to tap into the market.
However, Microsoft remains ahead in this race due to its $13 Bn investment in OpenAI. Consequently, it has an exclusive licence to use the underlying model of the groundbreaking technology, although others can receive outputs from the public API. Microsoft’s Copilot currently uses the more advanced GPT-4 Turbo LLM, resulting in enhanced AI capabilities.
Indian tech companies are not far behind. A handful of homegrown conglomerates, such as Reliance (Jio), TCS, Infosys and Mahindra & Mahindra, are already working on a slew of GenAI projects. A NASSCOM-BCG report estimates that the country’s AI market may reach $17 Bn by 2027, growing at an annualised rate of 25-30% during 2024-2027.
But this time, the credit for developing an India-focussed equivalent of ChatGPT goes to the Bengaluru-based GenAI startup CoRover.ai. Powered by proprietary cognitive AI technology, the startup launched BharatGPT in December 2023, claiming it to be India’s first-ever large language model. To be sure, it is one of the largest GenAI conversational platforms, gaining traction from more than a billion users in less than six months.
As GenAI platforms produce new content by processing massive amounts of existing data used to train algorithms, their output – in spite of its near-human excellence – mimics what we already know or tend to perceive. Because most of the training material is in English and comes from Western resources, these tools often fail to serve a diversified global audience or identify cultural nuances.
That is why global versions of GenAI applications may not always be adequate for India-specific queries, exposing algorithmic biases against the country’s societal contexts.
Here is a quick experiment we carried out at Inc42 to understand how GenAI falls short of community expectations. When we asked Copilot Designer (an image creator tool powered by OpenAI’s DALL-E) for a portrait of Lord Rama, the images it produced resembled Greek gods whom none of us could recognise as the iconic Indian figure.
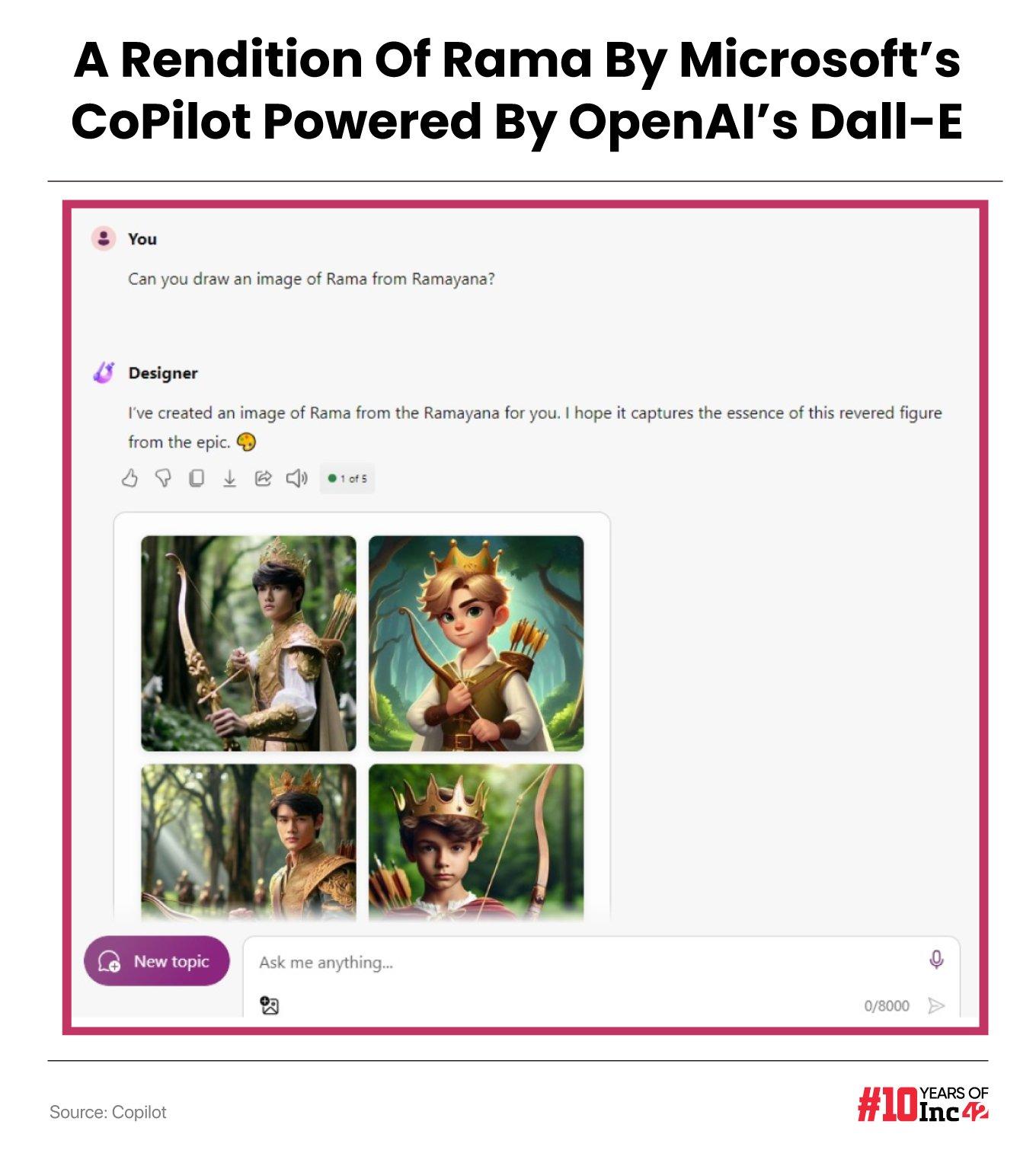
Such examples abound, not only in the Indian context but elsewhere. Google had to halt Gemini AI’s image generation capabilities earlier this year after it was blasted on social media for producing historically inaccurate images.
Recognising this socio-cultural gap in existing systems, entrepreneurs and developers from India have started working on a GenAI ecosystem tailored for Indian consumption, therefore yielding better contextual outputs across all formats.
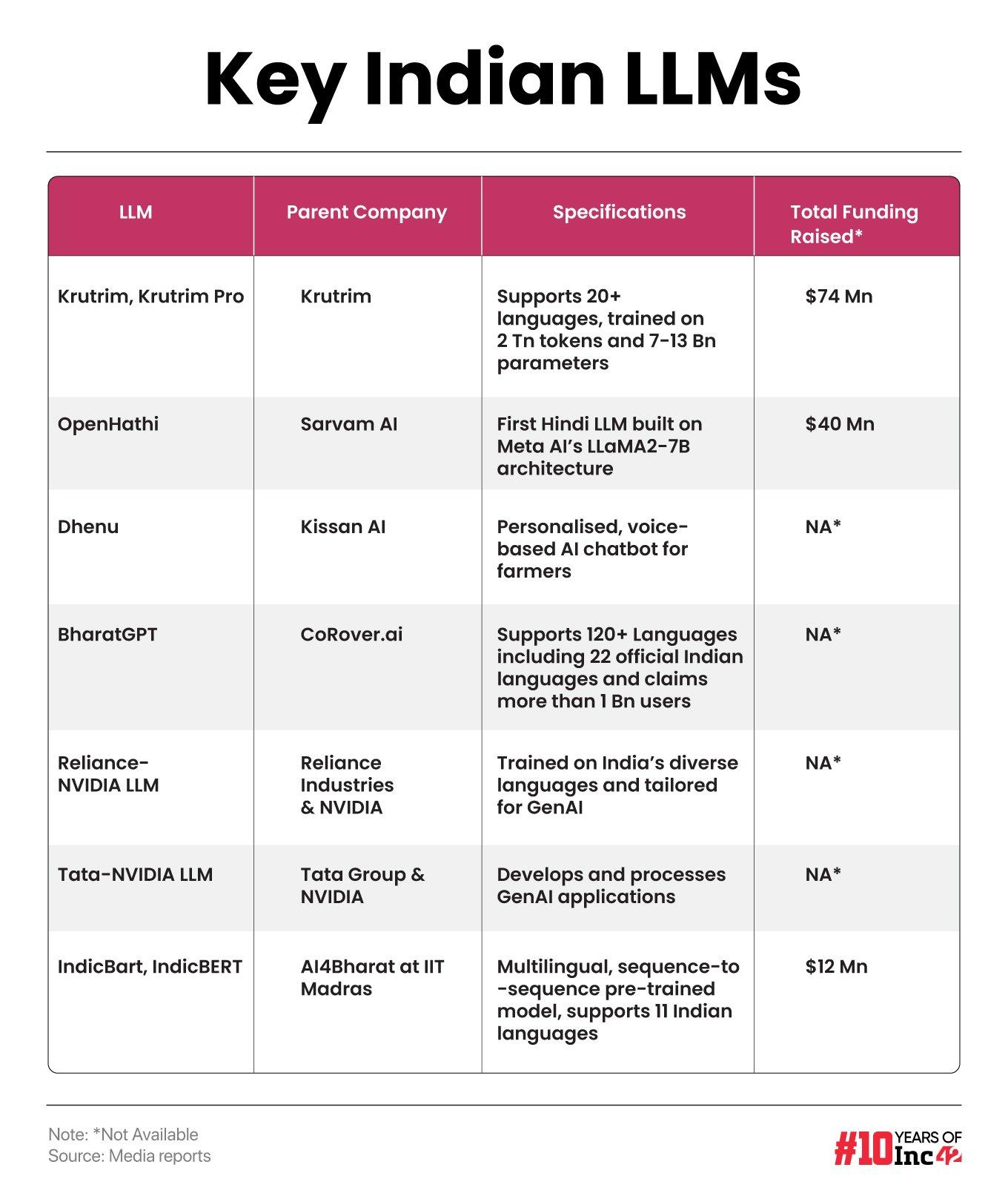
The need for India-focussed GenAI platforms led to a host of indigenous developments, such as BharatGPT, Ola Krutrim, and Project Indus (a Tech Mahindra venture including 40 different Indic languages). Each initiative is trying to overcome the language challenges pan-Indian users are bound to face in real life and now in the AI world.
“The idea is to provide equal access to knowledge and information to all Indians regardless of their background,” says Ankush Sabharwal, founder and CEO of CoRover.ai.
To avoid any misunderstanding, let us clarify that Sabharwal’s flagship GenAI BharatGPT must not be confused with Reliance Jio’s Bharat GPT. The confusion arose when Akash Ambani, chairman of Reliance Jio Infocomm, spoke at the IIT-Bombay Techfest 2023 and mentioned that the company was working with the premier institution to launch a homegrown AI model called Bharat GPT.
According to him, the programme is part of Reliance Jio’s broader vision (Jio 2.0) to create a comprehensive AI ecosystem.
On the other hand, CoRover.ai applied for the BharatGPT trademark in February 2023 and filed for a patent on the BharatGPT LLM model.
Inside CoRover’s BharatGPT
Before we delve deeper into the LLM’s benefits and use cases, a quick look at its tech components will not be out of context. BharatGPT (GPT stands for generative pre-trained transformers) typically contains encoders for encoding/inputting information and sequences for deep learning and decoders for generating new sequences based on the input. It is further fine-tuned for conversational applications with the help of supervised learning and, at times, human feedback.
The LLM also uses advanced techniques like word embedding for resource-efficient natural language processing. Simply put, word embedding is used in NLP for word vectorisation or converting words and phrases from human vocabulary into a set of real numbers, which is required for capturing syntactic and semantic information, text classification and text analysis.
For instance, the word ‘Apple’ could be used as a company name or as a fruit in different contexts. In such cases, word embedding can help capture the most appropriate meaning based on the language and the region, sector and domain, user and business details and specific use cases. Also, faster ML means less burden on GPUs and other computing resources.
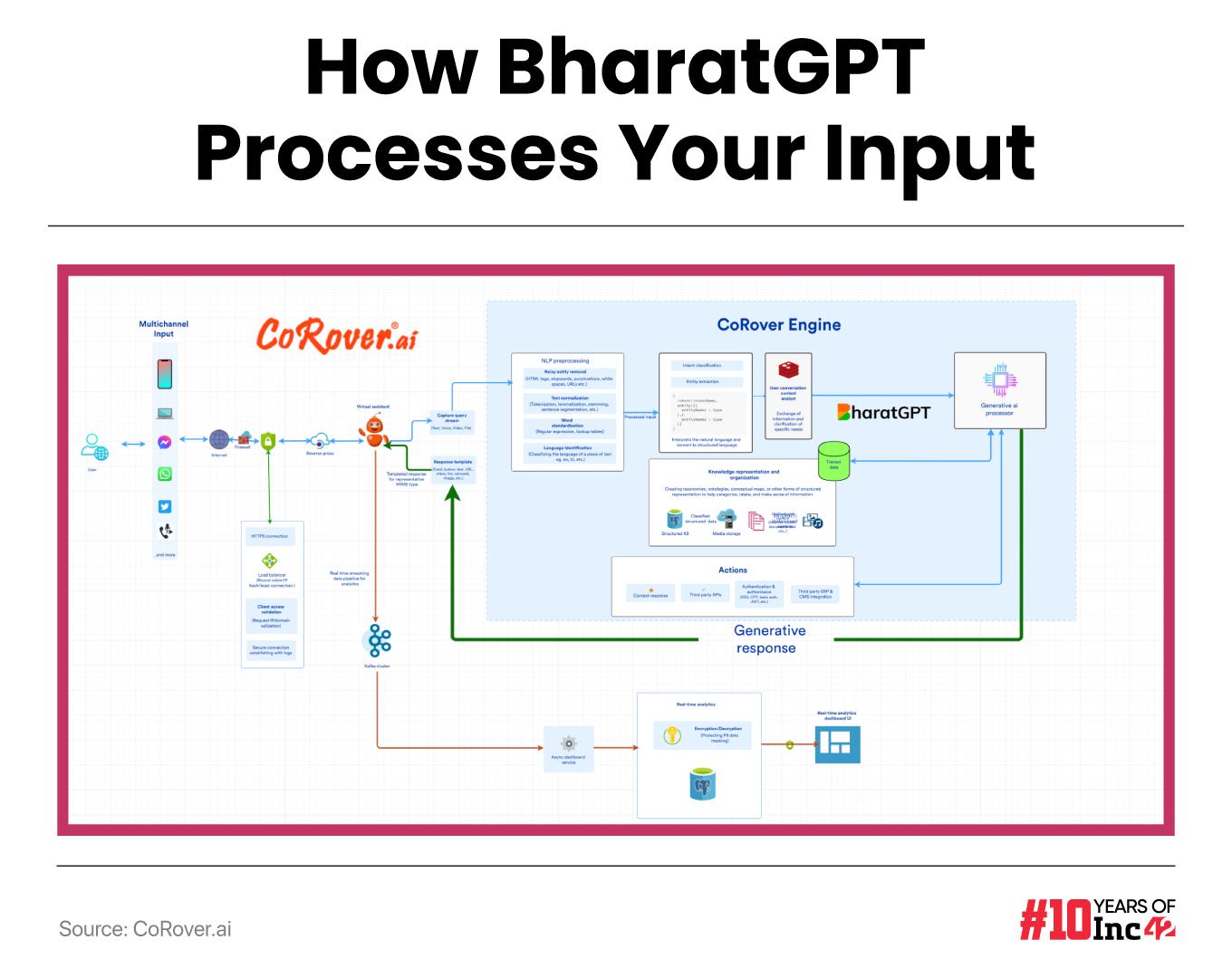
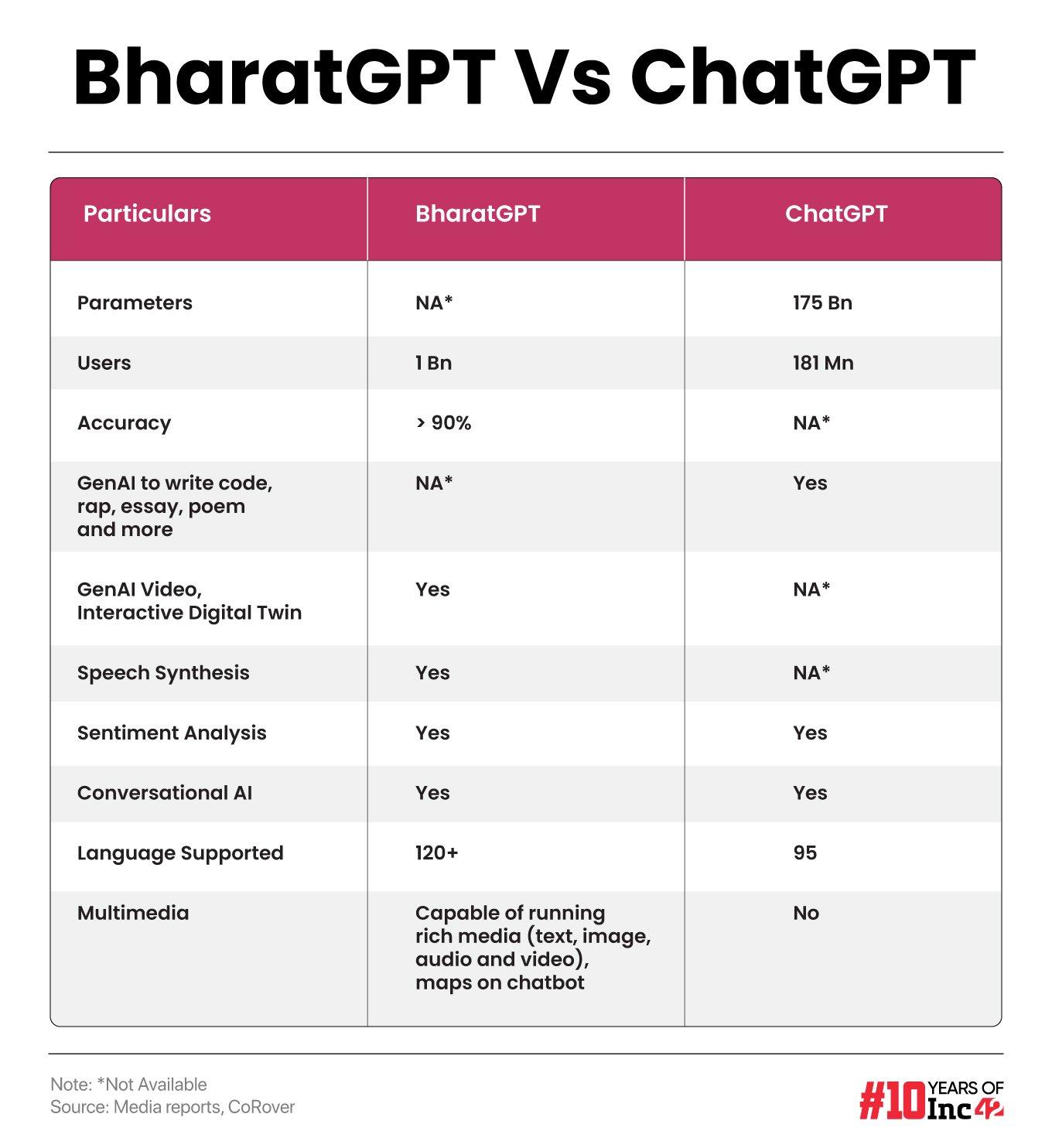
The multilingual application covering audio, video and text has been developed with the government-funded BHASHINI project, the National Language Translation Mission (NLTM) operating under MeitY. BharatGPT offers voice modality integration in more than 14 Indian languages and text modality in all 22 official Indian languages mentioned in the Indian Constitution. Globally, it supports 120+ languages compared to 80+, supported by ChatGPT.
BharatGPT enables a number of features, such as integration with payment gateways, Aadhaar-based eKYC authentication, dialogue management and sentiment analysis. It also claims an accuracy rate of 90%. More importantly, a homegrown LLM will focus more on data localisation, leading to better data security.

How BharatGPT Is Building Use Cases Across Enterprises
Unlike ChatGPT, CoRover’s BharatGPT has been designed for the B2B segment and it has paid rich dividends. “Currently, more than 60 organisations are using our services and we have received 900+ inbound leads so far,” claims Sabharwal, underscoring the startup’s early-mover advantage. The company has secured projects worth over INR 100 Cr scheduled for the next 12 months
It has already onboarded a host of industry leaders and storied organisations, such as LIC, NPCI, HUL, Oracle, Digital India, Mahindra & Mahindra, IRCTC, VRL, KSRTC and redBus. Others like SEBI, India’s capital market regulator, will soon integrate BharatGPT into their existing platforms.
Using the startup’s BharatGPT model, one can create text-, voice- and video-enabled multilingual virtual assistants (VAs) in no time by drawing information from content/documents specific to the business/use case. Depending on organisational requirements, data files are made accessible to the corresponding BharatGPT VA and generate answers and references from those resources.
Businesses can also integrate a custom knowledge base with enterprise resource planning (ERP) systems, customer relationship management (CRM) tools or application programming interfaces (APIs) for real-time transactions.
End consumers can start using a VA as soon as an organisation/business integrates the bot and facilitates engagement, says Sabharwal. Moreover, the end product is vertical, and the output solely depends on the data fed to a specific chatbot.
A look at an educational project brings further clarity here. If a chatbot built on BharatGPT is to be used for standard V learning, it will be primarily trained on standard V curricula and will respond in sync with the predetermined academic level. Ask a question on the same topic that requires more details expected from a standard XII student, and the response may not be adequate.
BharatGPT generates output based on curated training materials/datasets instead of relying on random resources. It also limits the scope of generating wrong output, as was the case with Copilot Designer or Google’s Gemini, and the accuracy level remains high.
Now, let us take a look at the website of National Payments Corporation of India (NPCI) to understand how the chatbot is operating in layers.
“If a person is asking pre-fed questions – say, from the FAQ list – the VA called Pai will respond directly. If Pai can’t fetch the response directly, it will use BharatGPT to come up with the answers, along with the references,” explained Sabharwal.
Similarly, CoRover, along with the Indian Railway Catering and Tourism Corporation (IRCTC), has developed another VA called RailGPT. The mobile application provides information, assistance and a bouquet of services to users while the bot understands user requests and responses in a conversational manner.
Interestingly, the startup recently announced it would shut down its overseas subsidiaries to focus more on the domestic market.
“Earlier, we opened companies in the US and the UK. Today, we are closing them down. We have requested our partners to handle the legal aspects. Of course, our long-term plan is to cater to those markets. But just now, we are experiencing significant demand here in India and want to prioritise the Indian market first,” said Sabharwal.
BharatGPT’s Multilingual Edge: Will It Nurture An Inclusive Culture?
According to a recent IBM survey, about 59% of Indian enterprises (companies with more than 1K employees) actively use AI in their businesses. Industry experts also think the country is poised to emerge as the largest market in the conversational AI segment, given its language census data. As per the 2011 census, India has 121 languages, each spoken by 10K people or more. Overall, more than 19.5K languages or dialects are spoken in this subcontinent.
In a polyglot nation like India, the inability to communicate in local languages can have a heavy impact on the economy. Many liken it to a tariff on trade, increasing the difficulty and costs of doing business across India. On the other hand, talent acquisition based solely on language proficiency has been expensive and inadequate for most companies.
In fact, language and cultural barriers have a profound social impact. Consider this: More than 50K people from Punjab, Uttar Pradesh, West Bengal, Bihar, Odisha and other states reside in Chennai and its suburbs. However, the majority of them do not speak Tamil and often face difficulties when interacting with the local police or registering complaints. Chennai Police also struggled to cope with this communication challenge, which impacted their investigations.
To address this issue, the state police department partnered with CoRover to launch video bot kiosks where users can communicate in multiple languages and GenAI tools can process the information efficiently.
“We have more than 130 Cr users who have access to our virtual assistants,” said Sabharwal. “If you ask me, we have the highest amount of data here, the Indian conversational data. We support the largest set of languages, whether Indian or global.”
As Sabharwal emphasises, one of the most important aspects of GenAI in the future will be improving access to information. Although 90% of the Indian population does not speak English, more than 90% of the information is currently only available in English, which is a substantial gap.
“With BharatGPT-like LLMs, people speaking different languages will have equal access to all available information,” he added.
The Bottom Line
According to research data by CB Insights, GenAI was the lone bright spot in 2023 amid a harsh funding winter, bagging 48% of the total AI investments, a substantial jump from a meagre 8% in the previous year. Despite a ‘down’ trend in deal size and count, AI startups worldwide raised $42.5 Bn in 2023 across 2.5K equity rounds.
Closer home, India’s GenAI market is expected to grow exponentially in the next few years, surpassing $17 Bn by 2030 from $1.1 Bn in 2023, growing at a CAGR of 48%, per an Inc42 report. The country’s startup ecosystem already comprises 70+ GenAI ventures and counting, pursuing the vision of ‘making AI in India’ and ‘making AI work for India.
With BharatGPT and its ilk (Ola Krutrim, Hanooman AI and more) taking charge and cementing their positions as the cornerstone of India’s conversational AI landscape, India is well prepared for a new era of digital empowerment, where language barriers are dissolved and access to information is democratised. It could be the beginning of a transformative future where AI augments human capabilities and creates an inclusive culture amid diversities to propel the nation towards economic and societal cohesion.
However, industry experts still doubt whether the world is ready for a large-scale GenAI makeover or if the current traction is another FOMO. The new technology has many challenges, from biases and inaccuracies to deepfakes and hallucinations, which can trigger disasters in a tech-driven, knowledge-centric world.
As IBM aptly points out in its survey, the top barriers to developing trustworthy and ethical AI are the lack of an AI strategy, company guidelines and AI governance and management tools that work across all data environments. Unless these are addressed, grandiose predictions may turn into zany outcomes in a dystopian world.
[Edited by Sanghamitra Mandal]